(1) Información redundante de la señal de video
Tomando el formato del componente YUV de grabación de video digital como ejemplo, YUV representa el brillo y dos señales de diferencia de color, respectivamente. Por ejemplo, para el sistema pal TV existente, la frecuencia de muestreo de la señal de luminancia es 13.5 mhz; la banda de frecuencia de la señal de croma suele ser la mitad o menos de la señal de brillo, que es de 6.75 mhz o 3.375 mhz. Tomando la frecuencia de muestreo de 4: 2: 2 como ejemplo, la señal Y adopta 13.5 mhz, la señal cromática U y V se muestrean en 6.75 mhz, y la señal de muestreo se cuantifica en 8 bits, luego se puede calcular la tasa de código de video digital como sigue:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216 Mbit / s
Si se almacena o se transmite directamente una cantidad tan grande de datos, será difícil utilizar la tecnología de compresión para reducir la tasa de bits. La señal de video digital se puede comprimir de acuerdo con dos condiciones básicas:
L. redundancia de datos. Por ejemplo, redundancia espacial, redundancia de tiempo, redundancia de estructura, redundancia de entropía de información, etc., es decir, existe una fuerte correlación entre los píxeles de la imagen. La eliminación de esta redundancia no conduce a la pérdida de información y es una compresión sin pérdidas.
L. redundancia visual. Algunas características de los ojos humanos, como el umbral de discriminación de brillo, el umbral visual, son diferentes en sensibilidad al brillo y croma, lo que hace imposible introducir errores apropiados en la codificación y no se detectarán. Las características visuales de los ojos humanos se pueden utilizar para intercambiar datos por compresión con cierta distorsión objetiva. Esta compresión tiene pérdidas.
La compresión de la señal de video digital se basa en las dos condiciones anteriores, lo que hace que los datos de video estén muy comprimidos, lo que favorece la transmisión y el almacenamiento. Los métodos comunes de compresión de video digital son la codificación mixta, que consiste en combinar la codificación de transformación, la estimación de movimiento y la compensación de movimiento, y la codificación de entropía para comprimir la codificación. Por lo general, la codificación de transformación se usa para eliminar la redundancia intracuadro de la imagen, y la estimación de movimiento y la compensación de movimiento se usan para eliminar la redundancia entre cuadros de la imagen, y la codificación de entropía se usa para mejorar aún más la eficiencia de compresión. Los siguientes tres métodos de codificación de compresión se presentan brevemente.
(a) Método de codificación por compresión
(b) Transformar la codificación
La función de la codificación de transformación es transformar la señal de imagen descrita en el dominio del espacio en el dominio de la frecuencia y luego codificar los coeficientes transformados. En términos generales, la imagen tiene una fuerte correlación en el espacio, y la transformación al dominio de frecuencia puede realizar la descorrelación y la concentración de energía. La transformada ortogonal común incluye la transformada discreta de Fourier, la transformada discreta del coseno, etc. La transformación de coseno discreta se usa ampliamente en la compresión de video digital.
La transformada de coseno discreta se conoce como transformada DCT. Puede transformar el bloque de imagen de L * l del dominio del espacio al dominio de la frecuencia. Por lo tanto, en el proceso de compresión y codificación de imágenes basadas en DCT, la imagen debe dividirse en bloques de imágenes que no se superpongan. Supongamos que el tamaño de una imagen es de 1280 * 720, se divide en bloques de imagen de 160 * 90 con un tamaño de 8 * 8 sin superponerse en forma de cuadrícula. Luego, la transformación DCT se puede realizar para cada bloque de imagen.
Después de dividir el bloque, cada bloque de imagen de 8 * 8 puntos se envía al codificador DCT, y el bloque de imagen de 8 * 8 se transforma del dominio espacial al dominio de frecuencia. La siguiente figura muestra un ejemplo de un bloque de imagen de 8 * 8 en el que el número representa el valor de brillo de cada píxel. Puede verse en la figura que los valores de brillo de cada píxel en este bloque de imagen son relativamente uniformes, especialmente el valor de brillo de los píxeles adyacentes no es muy grande, lo que indica que la señal de imagen tiene una fuerte correlación.
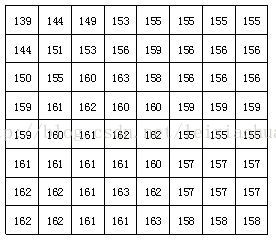
Un bloque de imagen real de 8 * 8
La siguiente figura muestra los resultados de la transformación DCT del bloque de imagen en la figura anterior. Se puede ver en la figura que después de la transformación DCT, el coeficiente de baja frecuencia en la esquina superior izquierda concentra mucha energía, mientras que la energía en el coeficiente de alta frecuencia en la esquina inferior derecha es muy pequeña.
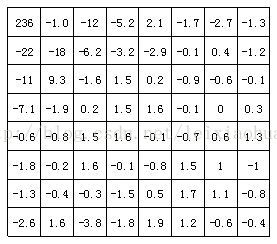
Los coeficientes del bloque de imagen después de la transformación DCT
La señal debe cuantificarse después de la transformación DCT. Debido a que los ojos humanos son sensibles a las características de baja frecuencia de las imágenes, como el brillo general de los objetos, y no a los detalles de alta frecuencia en la imagen, en el proceso de transmisión, la información de alta frecuencia se puede transmitir menos o no, solo la parte de baja frecuencia. El proceso de cuantificación reduce la transmisión de información al cuantificar los coeficientes de la región de baja frecuencia y la cuantificación aproximada de los coeficientes en la región de alta frecuencia, lo que elimina la información de alta frecuencia que no es sensible a los ojos humanos. Por lo tanto, la cuantificación es un proceso de compresión con pérdidas y la principal razón del daño a la calidad en la codificación de compresión de video.
El proceso de cuantificación se puede expresar mediante la siguiente fórmula:

Entre ellos, FQ (U, V) representa el coeficiente DCT después de la cuantificación; f (U, V) representa el coeficiente DCT antes de la cuantificación; Q (U, V) representa la matriz de ponderación de cuantificación; q es el paso de cuantificación; round se refiere a la consolidación, y el valor que se va a generar se toma como el valor entero más cercano.
Seleccione el coeficiente de cuantificación razonablemente, y el resultado después de cuantificar el bloque de imagen transformado se muestra en la figura.

Coeficiente DCT después de la cuantificación
La mayoría de los coeficientes DCT se cambian a 0 después de la cuantificación, mientras que solo unos pocos coeficientes son valores distintos de cero. En este momento, solo estos valores distintos de cero deben comprimirse y codificarse.
(b) Codificación de entropía
La codificación de entropía se nombra porque la longitud promedio del código después de la codificación está cerca del valor de entropía de la fuente. La codificación de entropía se implementa mediante VLC (codificación de longitud variable). El principio básico es dar un código corto al símbolo con alta probabilidad en la fuente, y dar un código largo al símbolo con una pequeña probabilidad de ocurrencia, para obtener estadísticamente la longitud de código promedio más corta. La codificación de longitud variable generalmente incluye código Hoffman, código aritmético, código de ejecución, etc. La codificación de longitud de ejecución es un método de compresión muy simple, su eficiencia de compresión no es alta, pero la velocidad de codificación y decodificación es rápida y todavía se usa ampliamente, especialmente después de la transformación de la codificación, utilizando la codificación de longitud de ejecución, tiene un buen efecto.
Primero, el coeficiente de CA que sigue inmediatamente al coeficiente de CC de salida del cuantificador se escaneará en tipo Z (como se muestra en la línea de flecha). El Z-scan transforma el coeficiente de cuantificación bidimensional en una secuencia unidimensional y luego continúa con la codificación de la longitud de ejecución. Finalmente, se usa otro código de longitud variable para codificar los datos después de la codificación de ejecución, como la codificación Hoffman. Mediante este tipo de codificación de longitud variable, se mejora aún más la eficiencia de la codificación.
(c) Estimación de movimiento y compensación de movimiento
La estimación de movimiento y la compensación de movimiento son métodos efectivos para eliminar la correlación de la dirección temporal de las secuencias de imágenes. Los métodos de codificación de entropía, cuantificación y transformación DCT descritos anteriormente se basan en una imagen de cuadro. Mediante estos métodos, se puede eliminar la correlación espacial entre píxeles de la imagen. De hecho, además de la correlación espacial, la señal de la imagen tiene una correlación temporal. Por ejemplo, para video digital con fondo estático como la transmisión de noticias y un pequeño movimiento del cuerpo principal de la imagen, la diferencia entre cada imagen es muy pequeña y la correlación entre las imágenes es muy grande. En este caso, no necesitamos codificar cada imagen de cuadro por separado, sino que solo podemos codificar las partes cambiadas de cuadros de video adyacentes, para reducir aún más la cantidad de datos. Este trabajo se realiza mediante estimación de movimiento y compensación de movimiento.
La tecnología de estimación de movimiento generalmente divide la imagen de entrada actual en varios subbloques de imagen pequeños que no se superponen entre sí, por ejemplo, el tamaño de una imagen de cuadro es 1280 * 720.En primer lugar, se divide en 40 * 45 bloques de imagen con 16 * 16 tamaños que no se superponen entre sí en forma de cuadrícula, y luego, dentro del alcance de una ventana de búsqueda de la imagen anterior o la última imagen, busque un bloque para cada bloque de imagen para encontrar un bloque de imagen dentro del alcance de un ventana de búsqueda El bloque de imágenes más similar. El proceso de búsqueda se llama estimación de movimiento. Calculando la información de posición entre el bloque de imagen más similar y el bloque de imagen, se puede obtener un vector de movimiento. De esta manera, el bloque de imagen actual se puede restar del bloque de imagen más similar señalado por el vector de movimiento de la imagen de referencia, y se puede obtener un bloque de imagen residual. Debido a que cada valor de píxel en el bloque de imagen residual es muy pequeño, se puede obtener una relación de compresión más alta en la codificación de compresión. Este proceso de resta se llama compensación de movimiento.
Debido a que se necesita usar una imagen de referencia para la estimación del movimiento y la compensación del movimiento en el proceso de codificación, es muy importante seleccionar la imagen de referencia. Generalmente, el codificador divide cada entrada de imagen de cuadro en tres tipos diferentes de acuerdo con las diferentes imágenes de referencia: cuadro I (intra), cuadro B (predicción de guía) y cuadro P (predicción). Como se muestra en la figura.
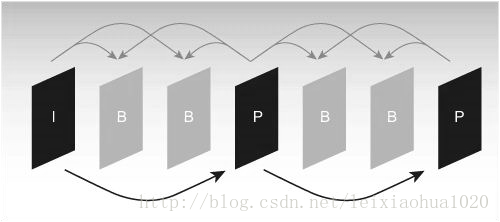
Secuencia típica de estructura de trama I, B, P
Como se muestra en la figura, la trama I solo usa los datos en la trama para codificar y no necesita estimación de movimiento ni compensación de movimiento durante el proceso de codificación. Obviamente, dado que I frame no elimina la correlación de la dirección del tiempo, la relación de compresión es relativamente baja. En el proceso de codificación, el cuadro P utiliza un cuadro I frontal o un cuadro P como imagen de referencia para la compensación de movimiento; de hecho, codifica la diferencia entre la imagen actual y la imagen de referencia. El modo de codificación de la trama B es similar a la trama P, la única diferencia es que necesita usar una trama I frontal o trama P y una trama I o trama P posterior para predecir durante el proceso de codificación. Por tanto, cada codificación de cuadro P necesita utilizar una imagen de cuadro como imagen de referencia, mientras que el cuadro B necesita dos cuadros como referencia. Por el contrario, el cuadro B tiene una relación de compresión más alta que el cuadro P.
(d) Codificación mixta
El documento presenta varios métodos importantes en la compresión y codificación de video. En la aplicación práctica, estos métodos no están separados y generalmente se combinan para lograr el mejor efecto de compresión. La siguiente figura muestra el modelo de codificación híbrida (es decir, codificación de transformación + estimación de movimiento y compensación de movimiento + codificación de entropía). El modelo es ampliamente utilizado en MPEG1, MPEG2, H.264 y otros estándares.En la figura, podemos ver que la imagen de entrada actual debe dividirse en bloques primero, el bloque de la imagen obtenida por el bloque se restará del imagen predicha después de la compensación de movimiento para obtener la imagen de diferencia x, y luego se llevan a cabo la transformación DCT y la cuantificación para el bloque de imagen de diferencia. Los datos de salida cuantificados tienen dos lugares diferentes: uno es enviarlos al codificador de entropía para su codificación, y el flujo de código codificado se envía a un caché Guarde en el dispositivo y espere la transmisión. Otra aplicación es contra cuantificar y revertir el cambio a la señal x ', que agrega la salida del bloque de imagen con compensación de movimiento para obtener una nueva señal de imagen de predicción, y envía un nuevo bloque de imagen de predicción a la memoria de cuadros.



|
|
|
|
¿A qué distancia (largo) de la cubierta del transmisor?
El alcance de transmisión depende de muchos factores. La distancia real se basa en la instalación de la antena de altura, ganancia de antena, utilizando como medio de construcción y otras obstrucciones, la sensibilidad del receptor, la antena del receptor. La instalación de la antena más alta y el uso en el campo, la distancia será mucho más lejos.
Transmisor FM 5W ejemplo, el uso en la ciudad y la ciudad natal:
Tengo un cliente de uso del transmisor FM con antena 5W EE.UU. GP en su ciudad natal, y lo prueba con un coche, es cubrir 10km (6.21mile).
Puedo probar el transmisor de FM con antena GP 5W en mi ciudad natal, que cubren alrededor 2km (1.24mile).
Puedo probar el transmisor de FM con antena 5W médico de cabecera en la ciudad de Guangzhou, que sólo cubren alrededor 300meter (984ft).
A continuación se presentan el intervalo aproximado de diferentes transmisores de FM de potencia. (El rango es de diámetro)
Transmisor FM 0.1W ~ 5W: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
Transmisor FM 15W ~ 80W: 3KM ~ 10KM
Transmisor FM 80W ~ 500W: 10KM ~ 30KM
Transmisor FM 500W ~ 1000W: 30KM ~ 50KM
Transmisor FM 1KW ~ 2KW: 50KM ~ 100KM
Transmisor FM 2KW ~ 5KW: 100KM ~ 150KM
Transmisor FM 5KW ~ 10KW: 150KM ~ 200KM
Cómo ponerse en contacto con nosotros para el transmisor?
Llámame + O 8618078869184
Envía un email [email protected]
1.How hasta dónde quiere cubrir de diámetro?
2.How alta de que la torre?
3.Where eres?
Y vamos a darle más consejo profesional.
Sobre Nosotros
FMUSER.ORG es una empresa de integración de sistemas que se enfoca en la transmisión inalámbrica de RF / equipos de audio / video de estudio / transmisión y procesamiento de datos. Ofrecemos todo tipo de asesoría, desde consultoría hasta la integración en rack, instalación, puesta en marcha y capacitación.
Ofrecemos transmisor de FM, transmisor de TV analógica, transmisor de TV digital, transmisor UHF VHF, antenas, conectores de cable coaxial, STL, procesamiento en el aire, productos de difusión para el estudio, monitoreo de señal RF, codificadores RDS, procesadores de audio y unidades de control de sitio remoto. Productos de IPTV, codificador / decodificador de video / audio, diseñados para satisfacer las necesidades de las grandes redes de transmisión internacionales y las pequeñas estaciones privadas.
Nuestra solución tiene estación de radio FM / estación de TV analógica / estación de TV digital / equipo de estudio de audio y video / enlace de transmisor de estudio / sistema de telemetría de transmisor / sistema de TV de hotel / transmisión en vivo de IPTV / transmisión en vivo de transmisión / videoconferencia / sistema de transmisión de CATV.
Estamos utilizando productos de tecnología avanzada para todos los sistemas, porque sabemos que la alta confiabilidad y el alto rendimiento son tan importantes para el sistema y la solución. Al mismo tiempo, también tenemos que asegurarnos de que nuestro sistema de productos tenga un precio muy razonable.
Tenemos clientes de emisoras públicas y comerciales, operadores de telecomunicaciones y autoridades de regulación, y también ofrecemos soluciones y productos a cientos de emisoras más pequeñas, locales y comunitarias.
FMUSER.ORG lleva más de 15 años exportando y tiene clientes en todo el mundo. Con 13 años de experiencia en este campo, contamos con un equipo profesional para resolver todo tipo de problemas del cliente. Nos dedicamos a ofrecer precios extremadamente razonables de productos y servicios profesionales. Email de contacto : [email protected]
Nuestra fábrica

Tenemos modernización de la fábrica. Que son bienvenidos a visitar nuestra fábrica cuando se llega a China.

En la actualidad, ya hay clientes 1095 en todo el mundo visitaron nuestra oficina Guangzhou Tianhe. Si usted viene a China, que son bienvenidos a visitarnos.
en la Feria

Esta es nuestra participación en 2012 Global Sources Hong Kong Electronics Fair . Los clientes de todo el mundo finalmente tener la oportunidad de reunirse.
¿Dónde está Fmuser?
Puede buscar estos números " 23.127460034623816,113.33224654197693 "en el mapa de Google, entonces puede encontrar nuestra oficina fmuser.
FMUSER oficina de Guangzhou se encuentra en el distrito de Tianhe, que es el centro del Cantón . Muy cerca En el correo electrónico “Su Cuenta de Usuario en su Nuevo Sistema XNUMXCX”. Feria de Cantón , Estación de tren de Guangzhou, Xiaobei carretera y Dashatou , solo necesito 10 minutos si toma TAXI . Bienvenidos amigos de todo el mundo a visitar y negociar.
Contacto: Blue Sky
Celular: + 8618078869184
WhatsApp: + 8618078869184
WeChat: + 8618078869184
E-mail: [email protected]
QQ: 727926717
Skype: sky198710021
Dirección: Sala de No.305 Huilan Edificio No.273 Huanpu carretera Guangzhou, China Código Postal: 510620
|
|
|
|
Inglés: Aceptamos todos los pagos, como PayPal, tarjeta de crédito, Western Union, Alipay, Money Bookers, T / T, LC, DP, DA, OA, Payoneer, si tiene alguna pregunta, comuníquese conmigo [email protected] o WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Recomendamos que utilice PayPal para comprar nuestros artículos, el PayPal es una forma segura para comprar en Internet.
Cada página de nuestra lista de elementos de fondo en la parte superior tienen un logotipo de PayPal para pagar.
Tarjeta de crédito.Si usted no tiene PayPal, pero usted tiene tarjeta de crédito, también puede hacer clic en el botón amarillo de PayPal para pagar con su tarjeta de crédito.
-------------------------------------------------- -------------------
Pero si usted no tiene una tarjeta de crédito y no tener una cuenta de PayPal o difícil consiguió un accout PayPal, puede utilizar lo siguiente:
Western Union.  www.westernunion.com www.westernunion.com
Pagar por Western Union a mí:
Nombre / Nombre: Yingfeng
Apellido / Apellido / Nombre familiar: Zhang
Nombre completo: Yingfeng Zhang
País: China
Ciudad: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Pagado por T / T (transferencia bancaria / transferencia telegráfica / transferencia bancaria)
Primera INFORMACIÓN BANCARIA (CUENTA DE LA EMPRESA):
SWIFT BIC: BKCHHKHHXXX
Nombre del banco: BANK OF CHINA (HONG KONG) LIMITED, HONG KONG
Dirección del banco: BANK OF CHINA TOWER, 1 GARDEN ROAD, CENTRAL, HONG KONG
CÓDIGO BANCO: 012
Nombre de cuenta: FMUSER INTERNATIONAL GROUP LIMITED
Cuenta NO. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Segunda INFORMACIÓN BANCARIA (CUENTA DE LA EMPRESA):
Beneficiario: Fmuser International Group Inc
Número de cuenta: 44050158090900000337
Banco del beneficiario: China Construction Bank Guangdong Branch
Código SWIFT: PCBCCNBJGDX
Dirección: NO.553 Tianhe Road, Guangzhou, Guangdong, Tianhe District, China
** Nota: Cuando transfiera dinero a nuestra cuenta bancaria, NO escriba nada en el área de comentarios; de lo contrario, no podremos recibir el pago debido a la política gubernamental sobre comercio internacional.
|
|
|
|
* Este documento se enviará en 1 2-días de trabajo cuando el pago claro.
* Enviaremos a su dirección de PayPal. Si usted quiere cambiar la dirección, por favor, envíe su dirección correcta y número de teléfono a mi correo electrónico [email protected]
* Si los paquetes se encuentra por debajo 2kg, nos enviarán a través de correo aéreo, tardará aproximadamente 15-25days a la mano.
Si el paquete es más que 2kg, enviaremos a través de EMS, DHL, UPS, Fedex entrega rápida expresa, tomará alrededor de 7 ~ 15days a su lado.
Si el paquete de más de 100kg, vamos a enviar por DHL o el flete aéreo. Se llevará a cerca 3 ~ 7days a su lado.
Todos los paquetes son la forma china de Guangzhou.
* El paquete se enviará como "regalo" y se eliminará lo menos posible, el comprador no tiene que pagar "IMPUESTOS".
* Después de la nave, le enviaremos un correo electrónico y le dará el número de seguimiento.
|
|
|
Para garantía.
Contáctenos --- >> Devuélvanos el artículo --- >> Reciba y envíe otro reemplazo.
Nombre: Liu xiaoxia
Dirección: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou, China.
Postal: 510620
Teléfono: + 8618078869184
Por favor, devuelva a esta dirección y escribir su PayPal, nombre, dirección problema en la nota: |
|













